Why Both Coronavirus and Climate Models Get It Wrong
/Most coronavirus epidemiological models have been an utter failure in providing advance information on the spread and containment of the insidious virus. Computer climate models are no better, with a dismal track record in predicting the future.
This post compares the similarities and differences of the two types of model. But similarities and differences aside, the models are still just that – models. Although I remarked in an earlier post that epidemiological models are much simpler than climate models, this doesn’t mean they’re any more accurate.
Both epidemiological and climate models start out, as they should, with what’s known. In the case of the COVID-19 pandemic the knowns include data on the progression of past flu epidemics, and demographics such as population size, age distribution, social contact patterns and school attendance. Among the knowns for climate models are present-day weather conditions, the global distribution of land and ice, atmospheric and ocean currents, and concentrations of greenhouse gases in the atmosphere.
But the major weakness of both types of model is that numerous assumptions must be made to incorporate the many variables that are not known. Coronavirus and climate models have little in common with the models used to design computer chips, or to simulate nuclear explosions as an alternative to actual testing of atomic bombs. In both these instances, the underlying science is understood so thoroughly that speculative assumptions in the models are unnecessary.
Epidemiological and climate models cope with the unknowns by creating simplified pictures of reality involving approximations. Approximations in the models take the form of adjustable numerical parameters, often derisively termed “fudge factors” by scientists and engineers. The famous mathematician John von Neumann once said, “With four [adjustable] parameters I can fit an elephant, and with five I can make him wiggle his trunk.”
One of the most important approximations in coronavirus models is the basic reproduction number R0 (“R naught”), which measures contagiousness. The numerical value of R0 signifies the number of other people that an infected individual can spread the disease to, in the absence of any intervention. As shown in the figure below, R0 for COVID-19 is thought to be in the range from 2 to 3, much higher than for a typical flu at about 1.3, though less than values for other infectious diseases such as measles.

It’s COVID-19’s high R0 that causes the virus to spread so easily, but its precise value is still uncertain. What determines how quickly the virus multiplies, however, is the incubation period, during which an infected individual can’t infect others. Both R0 and the incubation period define the epidemic growth rate. They’re adjustable parameters in coronavirus models, along with factors such as the rate at which susceptible individuals become infectious in the first place, travel patterns and any intervention measures taken.
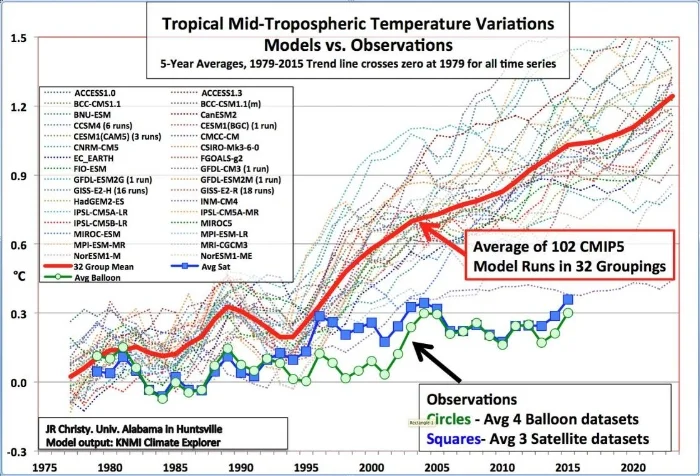
In climate models, hundreds of adjustable parameters are needed to account for deficiencies in our knowledge of the earth’s climate. Some of the biggest inadequacies are in the representation of clouds and their response to global warming. This is partly because we just don’t know much about the inner workings of clouds, and partly because actual clouds are much smaller than the finest grid scale that even the largest computers can accommodate – so clouds are simulated in the models by average values of size, altitude, number and geographic location. Approximations like these are a major weakness of climate models, especially in the important area of feedbacks from water vapor and clouds.
An even greater weakness in climate models is unknowns that aren’t approximated at all and are simply omitted from simulations because modelers don’t know how to model them. These unknowns include natural variability such as ocean oscillations and indirect solar effects. While climate models do endeavor to simulate various ocean cycles, the models are unable to predict the timing and climatic influence of cycles such as El Niño and La Niña, both of which cause drastic shifts in global climate, or the Pacific Decadal Oscillation. And the models make no attempt whatsoever to include indirect effects of the sun like those involving solar UV radiation or cosmic rays from deep space.
As a result of all these shortcomings, the predictions of coronavirus and climate models are wrong again and again. Climate models are known even by modelers to run hot, by 0.35 degrees Celsius (0.6 degrees Fahrenheit) or more above observed temperatures. Coronavirus models, when fed data from this week, can probably make a reasonably accurate forecast about the course of the pandemic next week – but not a month, two months or a year from now. Dr. Anthony Fauci of the U.S. White House Coronavirus Task Force recently admitted as much.
Computer models have a role to play in science, but we need to remember that most of them depend on a certain amount of guesswork. It’s a mistake, therefore, to base scientific policy decisions on models alone. There’s no substitute for actual, empirical evidence.
Next: How Science Is Being Misused in the Coronavirus Pandemic